
Description
Model
Using Nvidia SegFormer (b0-sized) encoder pre-trained-only
- “hierarchical Transformer encoder”, “lightweight all-MLP decode head” (for segmentation)
- “pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset”
- “SegformerForSemanticSegmentation adds the all-MLP decoder head on top”
- Paper SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
- Paper Github
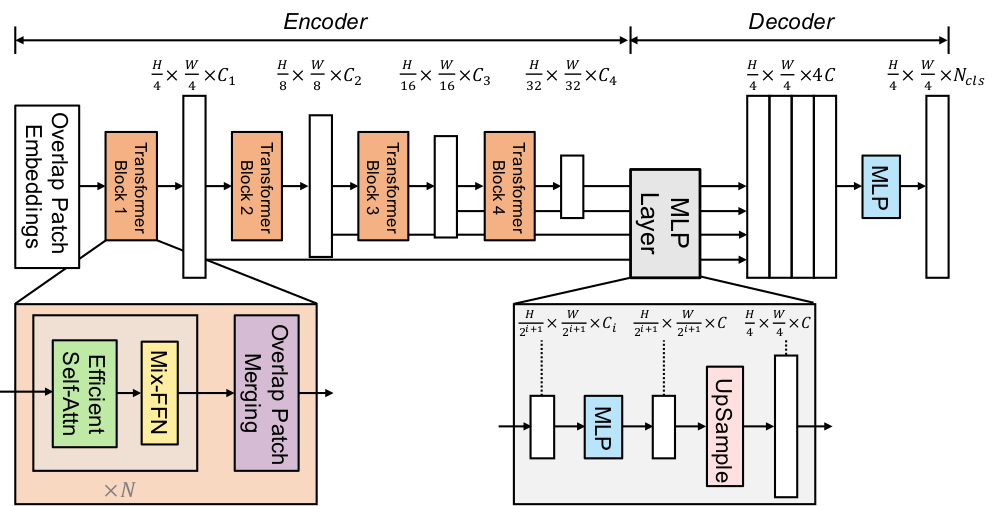
- SegFormer Model Architecture
Task
Using scene-parsing with Dataset scene_parse_150, a subset of semantic segmentation dataset MIT ADE20k
- “segment the whole image densely into semantic classes (image regions), where each pixel is assigned a class label”
- “mean of the pixel-wise accuracy and class-wise IoU as the final score”
- structure
{
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=683x512 at 0x1FF32A3EDA0>,
'annotation': <PIL.PngImagePlugin.PngImageFile image mode=L size=683x512 at 0x1FF32E5B978>,
'scene_category': 0
}
Execution order for model Trainer()
- Transform on-the-fly
* Data gets batch-wise prepared and augmented (
<dataset>.set_transform(<transform_fn>)) - Tokenize tansformed data (
image_processor) * Inputsimage,annotation(segmentation mask) andscene_category(label) * Outputspixel_valuesandlabelstensors - Collate tokenized batch data (
data_collator=collate_fn) * Returns stacked tensor of tokenized data batches - Fine-tune model with prepared data
* Also inputs
id2labelandlabel2id* Returns tensor of pixel-wise logits - Evaluate model output (
compute_metrics) * Compare output logits to input segmentation mask
Pseudo downstream forward run
from torch import no_grad
from transformers import (
AutoModelForImageClassification,
AutoImageProcessor
)
image_processor = AutoImageProcessor.from_pretrained(checkpoint)
model = AutoModelForImageClassification.from_pretrained(checkpoint)
# preprocess and tokenize, return PyTorch tensors
inputs = image_processor(image.convert("RGB"), return_tensors="pt")
# forward only
with no_grad():
outputs = model(**inputs)
logits = outputs.logits
pred_cls_idx = logits.argmax(-1).item()
print(f"{pred_cls_idx=}, {model.config.id2label[pred_cls_idx]=}")
Some weights of SegformerForSemanticSegmentation were not initialized
The following layers were not initialized because they should be fine-tuned to down-stream task.
- ‘decode_head.classifier.weight’
- ‘decode_head.batch_norm.bias’
- ‘decode_head.linear_c.3.proj.bias’
- ‘decode_head.batch_norm.running_mean’
- ‘decode_head.batch_norm.weight’
- ‘decode_head.batch_norm.running_var’
- ‘decode_head.linear_c.0.proj.weight’
- ‘decode_head.linear_c.1.proj.weight’
- ‘decode_head.classifier.bias’
- ‘decode_head.linear_c.1.proj.bias’
- ‘decode_head.linear_c.3.proj.weight’
- ‘decode_head.linear_c.2.proj.bias’
- ‘decode_head.linear_c.2.proj.weight’
- ‘decode_head.linear_fuse.weight’ac
- ‘decode_head.batch_norm.num_batches_tracked’
- ‘decode_head.linear_c.0.proj.bias’
In regards to the following warning:
Some weights of SegformerForSemanticSegmentation were not initialized from the model checkpoint at [...] are newly initialized because the shapes did not match:
- decode_head.classifier.weight: found shape torch.Size([150, 256, 1, 1]) in the checkpoint and torch.Size([151, 256, 1, 1]) in the model instantiated
- decode_head.classifier.bias: found shape torch.Size([150]) in the checkpoint and torch.Size([151]) in the model instantiated
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.