Segformerbaseline Finetuning Results
June 8, 2024

Recap on ML
June 8, 2024
May 27, 2024
May 5, 2024
ValueError: SegformerForImageClassification does not support device_map='auto'. To implement support, the modelclass needs to implement the _no_split_modules attribute.
and
ValueError: SegformerForImageClassification does not support device_map='sequential'. To implement support, the modelclass needs to implement the _no_split_modules attribute.
from_pretrained() supports device_map='auto', but not SegformerForImageClassificationdevice_map=0 (cuda:0) as default param into SegformerForImageClassification.from_pretrained()RuntimeError: Input type (float) and bias type (c10::Half) should be the same
copy() input dict and half() the pixel_valuesRuntimeError: "slow_conv2d_cpu" not implemented for 'Half'
UserWarning: Input type into Linear4bit is torch.float16, but bnb_4bit_compute_type=torch.float32 (default). This will lead to slow inference or training speed.
BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=<dtpype>)RuntimeError: Input type (float) and bias type (c10::Half) should be the same
collate_fn with tensor.half()ValueError: The model you want to train is loaded in 8-bit precision. if you want to fine-tune an 8-bit model, please make sure that you have installed bitsandbytes>=0.37.2.
Trainer() despite having bitsandbytes>=0.37.0 installed and imported, e.g. %pip list | grep bitsandbytes yields bitsandbytes 0.41.1UserWarning: You are calling save_pretrained to a 8-bit converted model you may likely encounter unexepected behaviors. If you want to save 8-bit models, make sure to have bitsandbytes>0.37.2 installed.
NotImplementedError: You are calling save_pretrained on a 4-bit converted model. This is currently not supported
RuntimeError: Loading a quantized checkpoint into non-quantized Linear8bitLt is not supported. Please call module.cuda() before module.load_state_dict()
Designing a device map
"auto", "balanced", "balanced_low_0", "sequential"accelerate.infer_auto_device_mapdevice_map=0 or device_map={'':torch.cuda.current_device()}May 5, 2024
8-bit quantization with bitsandbytes
From LLM.int8() Paper, Source GH. 8-bit HF inference example
bnb.optim.Adam8bit(....)bnb.nn.Embedding(..)linear = bnb.nn.Linear8bitLt(...)LLM.int8() methodBitsAndBytesConfig also offers configuration support.
from transformers import BitsAndBytesConfig
# quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=bf16)
nf4_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
)
torch.distributed.runMay 5, 2024
This is a writup to difficulties and errors encountered while working on a SegFormer PoC workbook.
ValueError: You passed along num_labels=1055 with an incompatible id to label map:{}
train_ds.features["scene_category"].num_classesto num_labels when len(id2label) expectedlen(id2label)RuntimeError: Error(s) in loading state_dict for SegformerForSemanticSegmentation: size mismatch for decode_head.classifier.weight: copying a param with shape torch.Size([150, 256, 1, 1]) from checkpoint, the shape in current model is torch.Size([151, 256, 1, 1]). size mismatch for decode_head.classifier.bias: copying a param with shape torch.Size([150]) from checkpoint, the shape in current model is torch.Size([151]). You may consider adding ignore_mismatched_sizes=True in the model from_pretrained method.
ignore_mismatched_sizes=True- decode_head.classifier.weight: found shape torch.Size([150, 256, 1, 1]) in the checkpoint and torch.Size([151, 256, 1, 1]) in the model instantiated - decode_head.classifier.bias: found shape torch.Size([150]) in the checkpoint and torch.Size([151]) in the model instantiatedNotImplementedError: Cannot copy out of meta tensor; no data!
device_map=dev in from_pretrained().accelerate.infer_auto_device_map(model) to model.hf_device_map after model is loadedHuggingFace Dataloader RuntimeError: cannot pin 'torch.cuda.FloatTensor' only dense CPU tensors can be pinned
.to(cuda) inside collator_fnOutOfMemoryError: CUDA out of memory. Tried to allocate 4.69 GiB (GPU 0; 14.75 GiB total capacity; 11.08 GiB already allocated; 2.48 GiB free; 11.23 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:256"per_device_train_batch_size=batch_size with batch_size from 32 to 8per_device_eval_batch_size=batch_size with batch_size from 32 to 1RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling cublasCreate(handle)
environ["PYTORCH_CUDA_ALLOC_CONF"] = "max_split_size_mb:2048" to max 1024RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
id2label or label2id, See CUDA runtime error (59) : device-side assert triggeredIndexError: Target 150 is out of bounds.IndexError: Target 150 is out of bounds.
torch._C._nn.cross_entropy_loss, See CUDA runtime error (59) : device-side assert triggered.len(categories) (150) smaller than train_ds.features['scene_category'].num_classes (1055) -> No.max([(i["labels"].min().item(), i["labels"].max().item()) for i in test_ds.shard(10, 0)]) yields (0, 150)id2label = {**{0:'NONE'}, **{k:v for k,v in enumerate(categories, 1)}}. Has to be used with ignore_mismatched_sizes=True in from_pretrained().RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
CUDA error: device-side assert triggered with CPU instead of CUDAdevice_map for cpuValueError: Unsupported number of image dimensions: 2
PIL.mode='RGB' (['RGB', 'RGB', 'RGB', 'RGB', 'RGB', 'RGB', 'RGB', 'RGB'])'pixel_values':torch.Size([<batch_size=8>, <chn_dim=3>, 512, 512])'labels':torch.Size([<batch_size=8>, 512, 512])PIL.mode like RGBA with 4 channels instead of RGB, See “Unsupported number of image dimensions” while using image_utils from Transformersimage.convert("RGB") on every image within the on-the-fly transform function train_transforms(example_batch)May 5, 2024
Using Nvidia SegFormer (b0-sized) encoder pre-trained-only
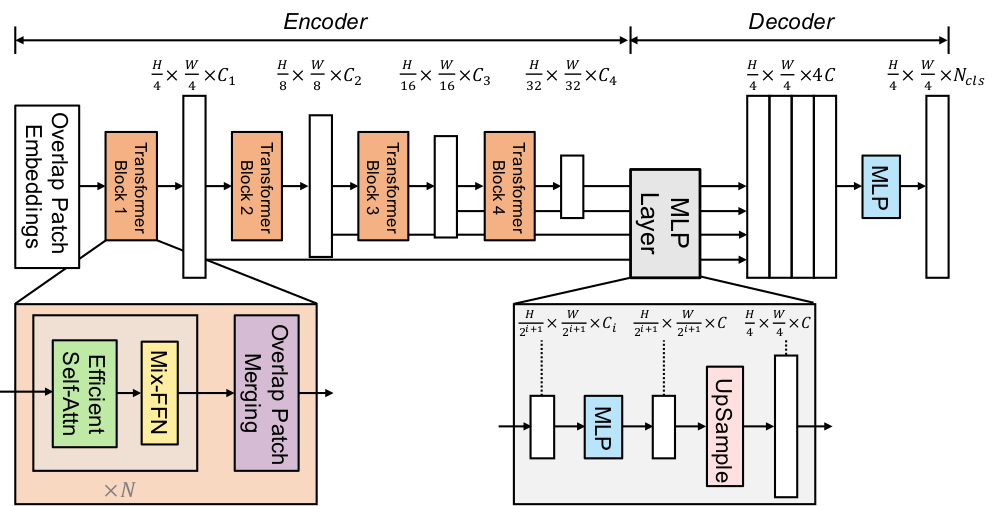
Using scene-parsing with Dataset scene_parse_150, a subset of semantic segmentation dataset MIT ADE20k
{
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=683x512 at 0x1FF32A3EDA0>,
'annotation': <PIL.PngImagePlugin.PngImageFile image mode=L size=683x512 at 0x1FF32E5B978>,
'scene_category': 0
}
Trainer()<dataset>.set_transform(<transform_fn>))image_processor)
* Inputs image, annotation (segmentation mask) and scene_category (label)
* Outputs pixel_values and labels tensorsdata_collator=collate_fn)
* Returns stacked tensor of tokenized data batchesid2label and label2id
* Returns tensor of pixel-wise logitscompute_metrics)
* Compare output logits to input segmentation maskfrom torch import no_grad
from transformers import (
AutoModelForImageClassification,
AutoImageProcessor
)
image_processor = AutoImageProcessor.from_pretrained(checkpoint)
model = AutoModelForImageClassification.from_pretrained(checkpoint)
# preprocess and tokenize, return PyTorch tensors
inputs = image_processor(image.convert("RGB"), return_tensors="pt")
# forward only
with no_grad():
outputs = model(**inputs)
logits = outputs.logits
pred_cls_idx = logits.argmax(-1).item()
print(f"{pred_cls_idx=}, {model.config.id2label[pred_cls_idx]=}")
The following layers were not initialized because they should be fine-tuned to down-stream task.
In regards to the following warning:
Some weights of SegformerForSemanticSegmentation were not initialized from the model checkpoint at [...] are newly initialized because the shapes did not match:
- decode_head.classifier.weight: found shape torch.Size([150, 256, 1, 1]) in the checkpoint and torch.Size([151, 256, 1, 1]) in the model instantiated
- decode_head.classifier.bias: found shape torch.Size([150]) in the checkpoint and torch.Size([151]) in the model instantiated
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.